
A Comprehensive Exploration of Pruning Techniques for Large Language Models: Enhancing Efficiency and Performance
Related Articles: A Comprehensive Exploration of Pruning Techniques for Large Language Models: Enhancing Efficiency and Performance
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to A Comprehensive Exploration of Pruning Techniques for Large Language Models: Enhancing Efficiency and Performance. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
A Comprehensive Exploration of Pruning Techniques for Large Language Models: Enhancing Efficiency and Performance

The field of natural language processing (NLP) has witnessed remarkable advancements with the advent of large language models (LLMs). These models, trained on massive datasets, exhibit exceptional capabilities in tasks such as text generation, translation, and question answering. However, their sheer size and complexity come with significant computational and resource demands. This has led researchers to explore methods for optimizing LLMs, particularly through pruning techniques.
Pruning, in essence, involves selectively removing components from a neural network while preserving its overall functionality. In the context of LLMs, this translates to eliminating unnecessary connections or neurons, leading to a more compact and efficient model. This reduction in size and complexity offers several benefits, including:
- Reduced computational cost: Smaller models require less processing power, enabling faster inference and reducing energy consumption.
- Improved memory efficiency: Compact models consume less memory, allowing for deployment on devices with limited resources.
- Enhanced generalization: Pruning can help mitigate overfitting by removing redundant or noisy components, leading to improved performance on unseen data.
- Faster training: Pruning can accelerate the training process by reducing the number of parameters that need to be updated.
Types of Pruning Techniques
Several pruning techniques have been developed and applied to LLMs, each targeting different aspects of the model’s structure and aiming to achieve specific goals. Some common approaches include:
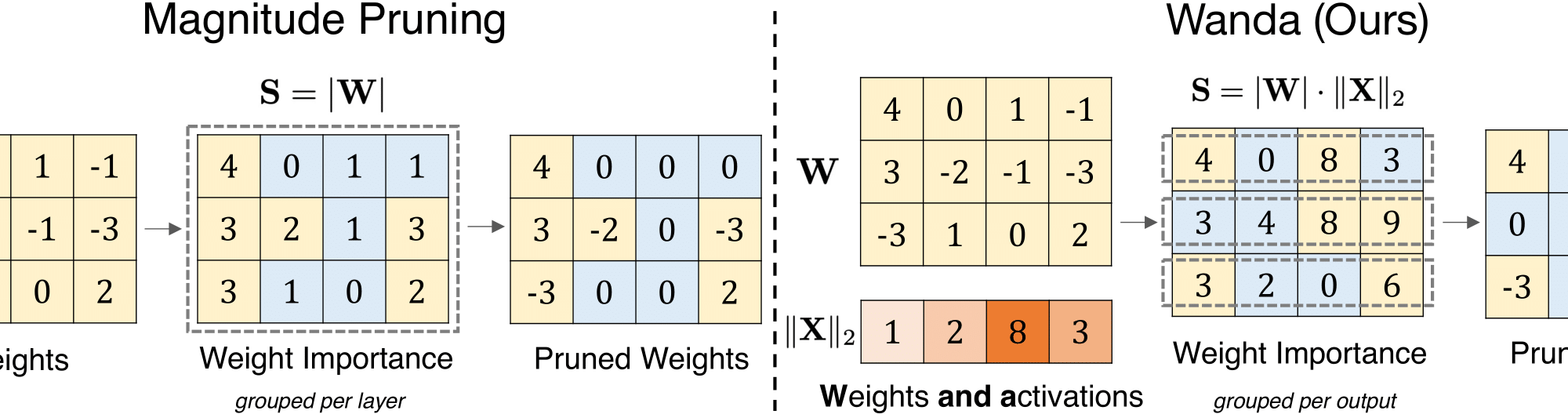
- Magnitude-based pruning: This method removes connections or neurons with low weights, assuming that these connections contribute less to the model’s overall performance.
- Activation-based pruning: This approach identifies and removes neurons that exhibit low activation during training or inference, suggesting their limited impact.
- Sensitivity-based pruning: This technique focuses on removing connections or neurons that have a minimal impact on the model’s output, as measured by sensitivity analysis.
- Structured pruning: This method prunes entire layers or blocks of neurons, potentially leading to significant model compression while maintaining performance.
EMA-Pruned VAEs: A Novel Approach to Pruning
One particularly promising technique, known as EMA-Pruned VAEs, leverages the power of variational autoencoders (VAEs) to facilitate efficient pruning. VAEs are generative models that learn a compressed representation of the input data, enabling reconstruction of the original data from this latent space.
EMA-Pruned VAEs operate by first training a VAE on the target dataset. This VAE learns a latent representation that captures the essence of the data, while simultaneously providing a mechanism for reconstructing the input. Subsequently, the VAE’s encoder network is pruned, using techniques like magnitude-based pruning or activation-based pruning. The pruned encoder is then used to generate new latent representations, which are fed into the decoder network for reconstruction.
This approach offers several advantages:
- Data-driven pruning: By leveraging the VAE’s latent representation, pruning decisions are guided by the underlying data distribution, ensuring that only truly redundant components are removed.
- Preservation of model functionality: The VAE’s decoder network acts as a safeguard, allowing reconstruction of the original data even after pruning the encoder, ensuring that the model’s essential capabilities are retained.
- Enhanced generalization: The VAE’s latent space representation can help to improve the model’s generalization performance by capturing the underlying structure of the data and reducing overfitting.
Benefits of EMA-Pruned VAEs
The application of EMA-Pruned VAEs has demonstrated significant benefits in various NLP tasks, including:
- Text generation: Pruned VAEs have been shown to generate more coherent and fluent text, while requiring less computational resources.
- Machine translation: Pruning has led to improved translation quality and reduced latency, making it more suitable for real-time applications.
- Sentiment analysis: Pruned VAEs have exhibited enhanced performance in classifying sentiment, particularly in resource-constrained environments.
- Question answering: Pruning has facilitated faster and more accurate responses to user queries, improving the efficiency of question answering systems.
FAQs on EMA-Pruned VAEs
Q: How does EMA-Pruned VAEs differ from traditional pruning methods?
A: EMA-Pruned VAEs leverage the generative capabilities of VAEs to guide the pruning process, ensuring that only truly redundant components are removed while preserving the model’s essential functionality. Traditional pruning methods often rely on heuristics or statistical measures, which may not always be optimal.
Q: What are the limitations of EMA-Pruned VAEs?
A: One limitation is the need to train a VAE, which can be computationally expensive. Additionally, the effectiveness of EMA-Pruned VAEs depends on the quality of the VAE’s latent representation, which can be influenced by the choice of architecture and training data.
Q: Are there any alternative approaches to pruning LLMs?
A: Yes, other pruning techniques exist, such as knowledge distillation and quantization. Knowledge distillation involves training a smaller student model to mimic the behavior of a larger teacher model. Quantization reduces the precision of the model’s weights, leading to a smaller footprint.
Tips for Implementing EMA-Pruned VAEs
- Choose the right VAE architecture: Select a VAE architecture that is suitable for the target task and data.
- Optimize the VAE training process: Ensure that the VAE is adequately trained to learn a robust latent representation.
- Experiment with different pruning techniques: Explore various pruning techniques to identify the most effective approach for your specific model and task.
- Evaluate the pruned model: Thoroughly evaluate the pruned model’s performance on various metrics to ensure that it meets the desired requirements.
Conclusion
EMA-Pruned VAEs represent a promising approach to pruning large language models, offering a balance between efficiency and performance. By leveraging the generative capabilities of VAEs, this technique enables the removal of unnecessary components while preserving the model’s essential functionality. This approach has the potential to significantly reduce computational cost, improve memory efficiency, and enhance generalization performance, making LLMs more practical and accessible for a wider range of applications. Further research and development in this area will continue to refine and optimize EMA-Pruned VAEs, paving the way for even more efficient and powerful NLP systems.






Closure
Thus, we hope this article has provided valuable insights into A Comprehensive Exploration of Pruning Techniques for Large Language Models: Enhancing Efficiency and Performance. We appreciate your attention to our article. See you in our next article!