
The Importance of Data Consistency: Understanding and Utilizing MapReduce Checksites
Related Articles: The Importance of Data Consistency: Understanding and Utilizing MapReduce Checksites
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to The Importance of Data Consistency: Understanding and Utilizing MapReduce Checksites. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
The Importance of Data Consistency: Understanding and Utilizing MapReduce Checksites

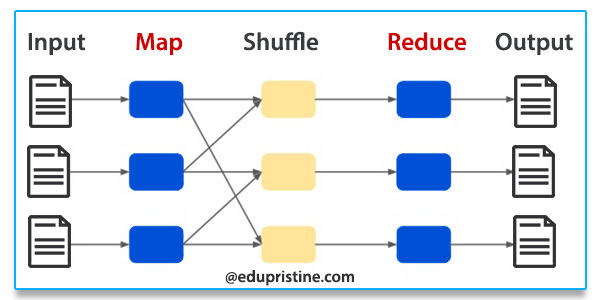
In the realm of distributed computing, particularly within the Hadoop ecosystem, ensuring data integrity and consistency is paramount. The MapReduce framework, a foundational component of Hadoop, offers a robust mechanism for achieving this through a process known as checksites. This article delves into the intricacies of checksites, exploring their significance, functionality, and the role they play in safeguarding data reliability within a distributed environment.
Understanding Checksites: A Foundation for Data Integrity
Checksites are essentially checkpoints within the MapReduce workflow, strategically placed at critical points to capture the state of the computation. These checkpoints, stored in a designated location within the cluster, serve as a safety net, allowing the system to recover gracefully in the event of failures.
The Mechanics of Checksites
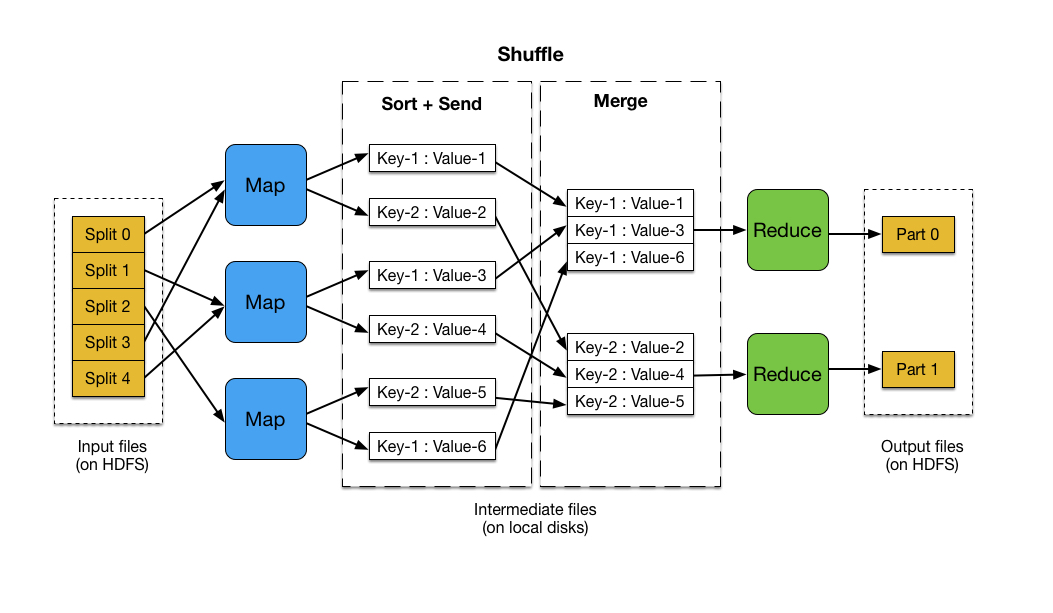
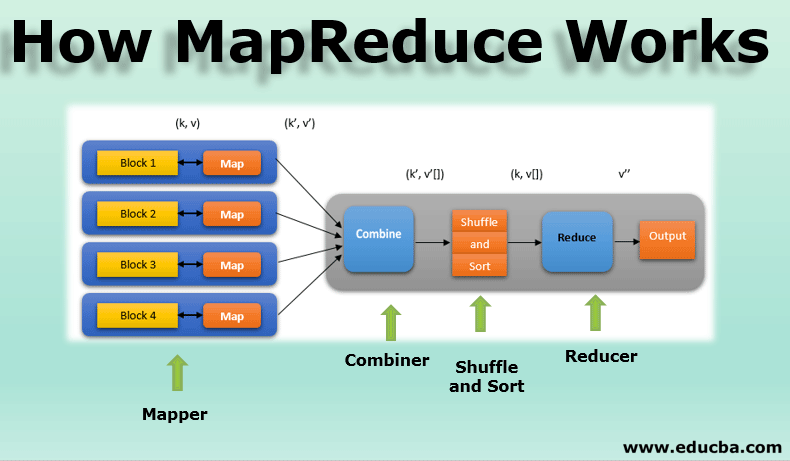
During a MapReduce job execution, data is processed in stages, with the output of each stage serving as input for the next. Checksites are created at the end of each stage, capturing the intermediate results. This snapshot of the computation’s progress is crucial for recovery.
The Benefits of Checksites:
-
Fault Tolerance: In the event of a node failure, checksites allow the MapReduce framework to restart the computation from the last successful checkpoint. This eliminates the need to reprocess the entire job, significantly reducing the time required for recovery.
-
Data Consistency: By periodically capturing the state of the computation, checksites ensure that the data remains consistent throughout the process. This is especially important in scenarios where data is being written to multiple nodes concurrently.
-
Enhanced Performance: While checksites do introduce a slight overhead, the benefits of faster recovery and increased data reliability far outweigh this cost. In fact, checksites can contribute to improved overall performance by reducing the time spent on error handling and data reprocessing.
Configuring and Utilizing Checksites
The frequency and location of checksites are configurable parameters within the MapReduce framework. Administrators can adjust these settings based on the specific requirements of the application and the cluster environment.
Factors Influencing Checksites Configuration:
-
Job Complexity: Jobs with complex data transformations and extensive processing may require more frequent checksites to mitigate the risk of data loss.
-
Cluster Size and Architecture: Larger clusters with numerous nodes may necessitate more frequent checksites to ensure timely recovery in the event of failures.
-
Data Sensitivity: For critical applications where data integrity is paramount, administrators may choose to increase the frequency of checksites to minimize the potential for data loss.
Understanding Checksites: A Practical Example
Consider a MapReduce job processing a massive dataset of customer transactions. The job involves multiple stages, including data aggregation, filtering, and analysis.
Without checksites, a node failure during any stage could result in the loss of all processed data up to that point. The job would need to be restarted from scratch, leading to significant delays and resource consumption.
With checksites, the system can recover from a node failure by restarting the computation from the last successful checkpoint. This ensures that only the data processed after the last checkpoint needs to be reprocessed, significantly reducing the recovery time and resource usage.
Troubleshooting Checksites: A Guide for Administrators
While checksites are a powerful tool for ensuring data integrity, challenges can arise. Understanding common issues and troubleshooting techniques is crucial for maintaining a healthy MapReduce environment.
Common Challenges:
-
Checksite Corruption: Corruption in checksite data can occur due to disk failures or other unforeseen circumstances. This can lead to errors during recovery, preventing the job from resuming correctly.
-
Checksite Storage Limitations: Insufficient storage space for checksites can lead to failures during the checksite creation process.
-
Incorrect Configuration: Improper configuration of checksites, such as setting an inappropriate frequency or location, can negatively impact performance and data reliability.
Troubleshooting Tips:
-
Monitor Checksite Creation: Regularly monitor the creation of checksites to identify any issues or errors.
-
Validate Checksite Integrity: Periodically validate the integrity of checksite data to ensure its accuracy and prevent data corruption.
-
Review Checksite Configuration: Ensure that the checksite configuration parameters are appropriate for the specific application and cluster environment.
-
Examine System Logs: Analyze system logs for any errors or warnings related to checksites to identify potential problems.
-
Utilize Diagnostic Tools: Leverage available diagnostic tools to investigate checksite-related issues and gather relevant information for troubleshooting.
FAQs about Checksites
1. What are the different types of checksites in MapReduce?
The MapReduce framework primarily uses two types of checksites:
- Task Checkpoints: Capturing the state of individual tasks within a MapReduce job.
- Job Checkpoints: Capturing the overall state of a MapReduce job, including the status of all tasks.
2. How often should checksites be created?
The frequency of checksite creation depends on factors such as job complexity, cluster size, and data sensitivity. Administrators should strike a balance between frequent checksites for data integrity and minimal performance overhead.
3. Where are checksites stored?
Checksites are typically stored in a designated directory within the Hadoop Distributed File System (HDFS). This location can be configured based on the specific requirements of the cluster environment.
4. What happens if a checksite is corrupted?
If a checksite is corrupted, the MapReduce framework may encounter errors during recovery. Administrators should investigate the cause of the corruption and take steps to restore the checksite data or re-run the affected tasks.
5. Can checksites be disabled?
While checksites provide significant benefits for data integrity and fault tolerance, they can be disabled if deemed unnecessary for a particular application. However, disabling checksites should be done with caution, as it increases the risk of data loss in the event of failures.
Conclusion: Checksites – A Cornerstone for Reliable Distributed Processing
Checksites are an essential component of the MapReduce framework, ensuring data integrity and fault tolerance in distributed computing environments. By strategically capturing the state of the computation at critical points, checksites enable seamless recovery from failures, minimizing data loss and downtime. Understanding the mechanics, benefits, and configuration of checksites is crucial for administrators seeking to optimize the performance and reliability of their Hadoop clusters. Utilizing checksites effectively strengthens the foundation of data integrity and paves the way for robust, efficient, and reliable distributed processing.




Closure
Thus, we hope this article has provided valuable insights into The Importance of Data Consistency: Understanding and Utilizing MapReduce Checksites. We appreciate your attention to our article. See you in our next article!