
The Phenomenon of Map Runaway: Understanding and Addressing Data Drift in Machine Learning
Related Articles: The Phenomenon of Map Runaway: Understanding and Addressing Data Drift in Machine Learning
Introduction
With great pleasure, we will explore the intriguing topic related to The Phenomenon of Map Runaway: Understanding and Addressing Data Drift in Machine Learning. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
The Phenomenon of Map Runaway: Understanding and Addressing Data Drift in Machine Learning
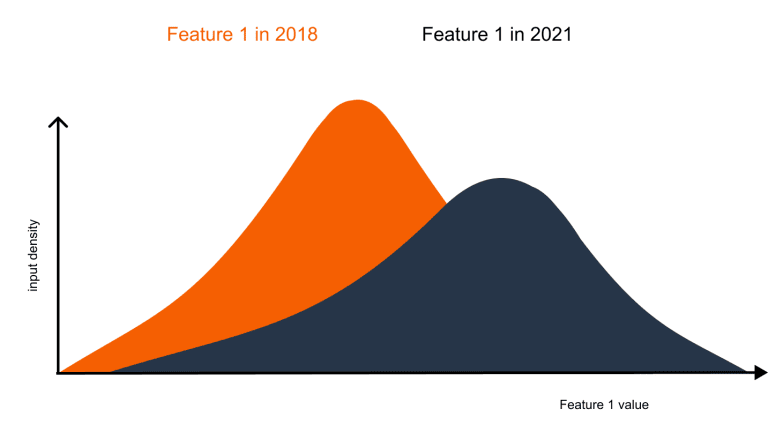
Machine learning models, powerful tools for analyzing and predicting complex patterns, rely on data. The quality and relevance of this data are crucial for the model’s performance. However, real-world data is dynamic, constantly evolving, and this evolution can lead to a phenomenon known as data drift. Data drift occurs when the distribution of the data used to train a model changes over time, rendering the model less accurate in its predictions. This phenomenon, often referred to as "map runaway," presents a significant challenge in maintaining the effectiveness of machine learning models.
Understanding Data Drift:
Data drift can manifest in various ways:
- Concept drift: The relationship between input features and the target variable changes. For example, a model trained to predict customer churn might become less accurate if customer behavior shifts due to a new product launch.
- Data drift: The distribution of input features changes. This could occur if a model trained on data from a specific region encounters data from a different region with distinct characteristics.
- Label drift: The definition of the target variable changes. For instance, a model trained to classify spam emails might become inaccurate if the definition of spam evolves.
The Consequences of Data Drift:
Data drift can have detrimental effects on machine learning models:
- Decreased Accuracy: As the model’s training data becomes less representative of the current data, its predictive accuracy deteriorates.
- Increased Costs: Re-training models to adapt to data drift requires significant time, resources, and expertise.
- Loss of Trust: Inaccurate predictions can erode user confidence and undermine the credibility of the model.
Addressing Data Drift:
Strategies for mitigating data drift can be categorized into two main approaches:
1. Proactive Strategies:
- Continuous Monitoring: Regularly monitoring the performance of the model and the characteristics of the input data allows for early detection of drift.
- Data Augmentation: Adding synthetic data that reflects the evolving characteristics of the real-world data can help maintain model accuracy.
- Model Retraining: Periodically retraining the model using updated data can ensure it remains aligned with the current data distribution.
2. Reactive Strategies:
- Adaptive Learning: Employing algorithms that can adapt to changing data patterns without requiring complete retraining.
- Ensemble Methods: Combining multiple models trained on different data subsets can improve robustness to drift.
- Data Re-weighting: Adjusting the weights of different data points based on their relevance to the current data distribution can improve model accuracy.
FAQs on Data Drift:
Q: How can I detect data drift?
A: Monitoring key performance indicators (KPIs) like accuracy, precision, and recall can signal drift. Analyzing the distribution of input features and comparing it to the training data can also reveal changes.
Q: How often should I re-train my model?
A: The frequency of retraining depends on the rate of change in the data and the model’s sensitivity to drift. Regular monitoring and performance evaluation can guide the retraining schedule.
Q: What are some tools for monitoring data drift?
A: There are numerous tools available for monitoring data drift, including open-source libraries like scikit-learn and commercial platforms like Amazon SageMaker.
Tips for Managing Data Drift:
- Establish a monitoring framework: Implement a system for continuous monitoring of model performance and data characteristics.
- Develop clear drift detection criteria: Define thresholds for key metrics that signal potential drift.
- Document data drift events: Record instances of drift, their causes, and the actions taken to address them.
- Prioritize data quality: Ensure the data used for training and monitoring is accurate, clean, and representative of the target population.
Conclusion:
Data drift is an inherent challenge in machine learning, but it is not insurmountable. By understanding the mechanisms of data drift and implementing appropriate strategies for detection and mitigation, we can ensure the continued effectiveness of machine learning models in real-world applications. Proactive monitoring, adaptive learning, and a commitment to data quality are essential for building robust and resilient machine learning systems.


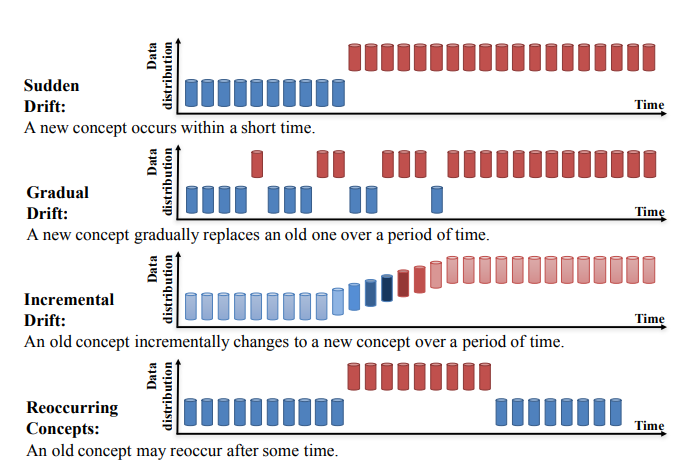



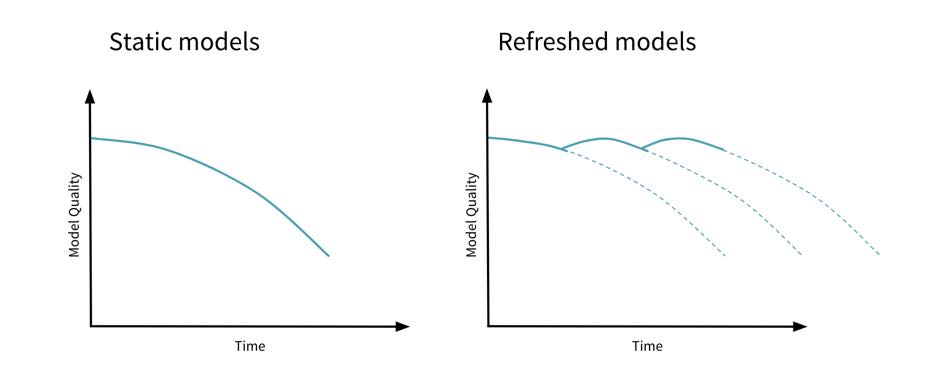
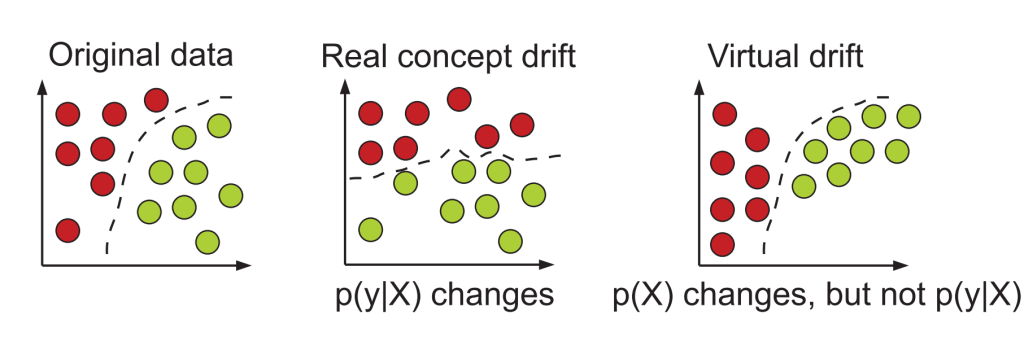
Closure
Thus, we hope this article has provided valuable insights into The Phenomenon of Map Runaway: Understanding and Addressing Data Drift in Machine Learning. We thank you for taking the time to read this article. See you in our next article!