
The Power of MapReduce: A Comprehensive Exploration of a Paradigm Shift in Data Processing
Related Articles: The Power of MapReduce: A Comprehensive Exploration of a Paradigm Shift in Data Processing
Introduction
With great pleasure, we will explore the intriguing topic related to The Power of MapReduce: A Comprehensive Exploration of a Paradigm Shift in Data Processing. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
The Power of MapReduce: A Comprehensive Exploration of a Paradigm Shift in Data Processing
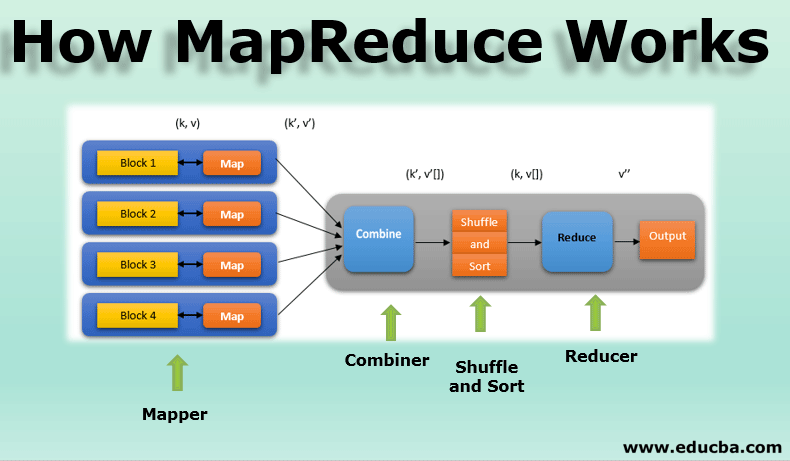
The advent of the internet and the exponential growth of data have ushered in a new era of data-driven decision making. This necessitates robust and efficient methods for processing vast amounts of data, a challenge that traditional data processing techniques struggle to address. Enter MapReduce, a paradigm shift in data processing that revolutionized the way we handle massive datasets.
Understanding MapReduce: A Framework for Parallel Data Processing
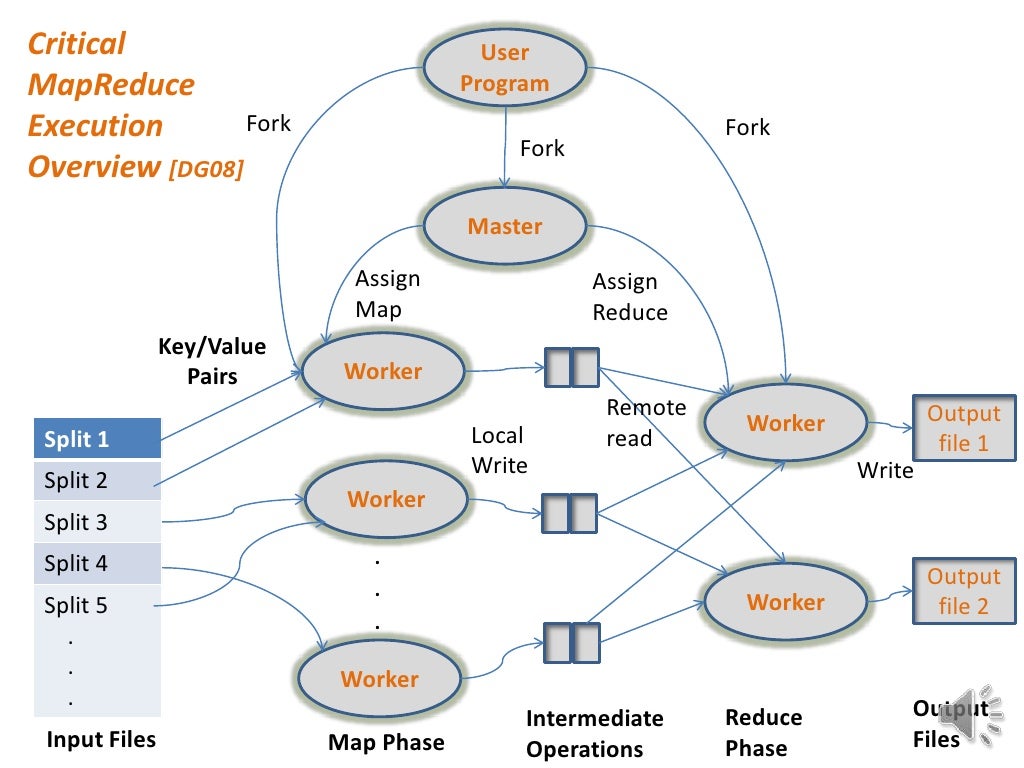
MapReduce is a programming model and a software framework that allows for the parallel processing of large datasets across a cluster of computers. It simplifies the complex task of distributed computing, enabling developers to focus on the core logic of their data processing tasks rather than the intricacies of distributed systems.
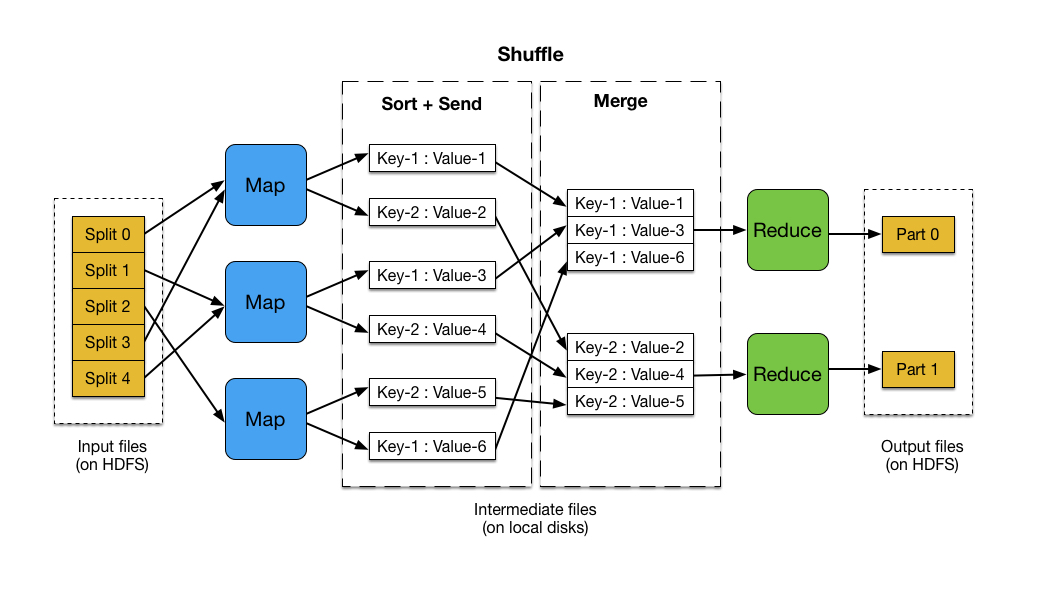
The framework operates in two distinct phases:
- Map: The "map" phase involves dividing the input data into smaller chunks, processing each chunk independently, and generating intermediate key-value pairs. This phase is highly parallelizable, allowing for simultaneous processing across multiple nodes.
- Reduce: The "reduce" phase takes the intermediate key-value pairs generated by the map phase, groups them by key, and applies a user-defined function to combine the values associated with each key. This phase further aggregates and summarizes the data, producing the final output.
Benefits of MapReduce: Efficiency, Scalability, and Fault Tolerance
The inherent parallelization of MapReduce offers significant advantages in terms of efficiency and scalability. By distributing the processing workload across multiple nodes, MapReduce can achieve significant speedups compared to traditional single-machine processing approaches. This scalability enables the processing of datasets that would be impossible to handle with conventional methods.
Furthermore, MapReduce is inherently fault-tolerant. If a node fails during processing, the framework automatically redistributes the workload to other available nodes, ensuring continued operation without significant disruption. This fault tolerance is crucial for maintaining data processing integrity in large-scale distributed environments.
Applications of MapReduce: A Wide Range of Use Cases
MapReduce finds applications in a wide range of domains, including:
- Search Engines: MapReduce powers the indexing and retrieval of vast amounts of data in search engines, allowing for efficient searching and ranking of results.
- Social Media Analysis: Analyzing user interactions, trends, and patterns in social media platforms requires processing massive datasets, which MapReduce handles effectively.
- E-commerce: Recommender systems and fraud detection in e-commerce platforms rely on MapReduce to analyze customer data and identify patterns for personalized recommendations and risk mitigation.
- Scientific Computing: Researchers in fields like genomics, astrophysics, and climate science use MapReduce to analyze large datasets, extract insights, and develop models.
- Log Analysis: MapReduce facilitates the analysis of large log files generated by servers and applications, enabling the identification of errors, performance bottlenecks, and security threats.
The Evolution of MapReduce: From Hadoop to Cloud Platforms
The original MapReduce framework was developed by Google and was initially implemented in the Hadoop open-source project. Hadoop provided a robust and open-source implementation of MapReduce, making it accessible to a wider audience.
However, with the rise of cloud computing, MapReduce has evolved further. Cloud providers like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer managed MapReduce services, simplifying deployment and management for users. These cloud-based platforms provide scalability, elasticity, and cost-effectiveness, making MapReduce more accessible and powerful than ever before.
FAQs about MapReduce
- What are the limitations of MapReduce? While MapReduce offers significant advantages, it also has limitations. It can be challenging to debug complex MapReduce jobs, and data shuffling between the map and reduce phases can introduce overhead.
- Is MapReduce still relevant in the era of big data? While newer frameworks like Spark and Flink have emerged, MapReduce remains relevant for certain use cases. Its simplicity and robust fault tolerance make it a suitable choice for batch processing tasks and scenarios where scalability and fault tolerance are paramount.
- How does MapReduce compare to other big data processing frameworks? MapReduce is often compared to frameworks like Spark and Flink, which offer more flexibility and performance for certain tasks. However, MapReduce remains a valuable tool for batch processing and scenarios where its simplicity and fault tolerance are critical.
Tips for Effective MapReduce Implementation
- Optimize Data Input and Output: Minimize data transfer between nodes to reduce overhead.
- Choose Appropriate Data Partitioning Strategies: Select a partitioning strategy that ensures efficient distribution of data across nodes.
- Use Combiners to Reduce Data Size: Employ combiners to aggregate intermediate values before they are sent to the reduce phase, minimizing network traffic.
- Implement Efficient Reduce Functions: Design efficient reduce functions that process data efficiently and produce the desired output.
- Monitor and Analyze Job Performance: Track job execution time, resource utilization, and other metrics to identify areas for optimization.
Conclusion: The Enduring Legacy of MapReduce
MapReduce has revolutionized data processing, enabling the efficient and scalable analysis of massive datasets. Its simplicity, fault tolerance, and wide range of applications have made it a cornerstone of big data processing. While newer frameworks have emerged, MapReduce remains a valuable tool for batch processing and scenarios where its strengths are crucial. As the volume of data continues to grow exponentially, MapReduce’s legacy will undoubtedly continue to shape the future of data processing.





Closure
Thus, we hope this article has provided valuable insights into The Power of MapReduce: A Comprehensive Exploration of a Paradigm Shift in Data Processing. We appreciate your attention to our article. See you in our next article!