
The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers
Related Articles: The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers
- 2 Introduction
- 3 The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers
- 3.1 Understanding the Fundamentals
- 3.2 The Advantages of mmap Ring Buffers
- 3.3 Applications of mmap Ring Buffers
- 3.4 Implementing mmap Ring Buffers
- 3.5 FAQs: Addressing Common Questions
- 3.6 Tips for Effective Implementation
- 3.7 Conclusion: The Power of Shared Memory
- 4 Closure
The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers
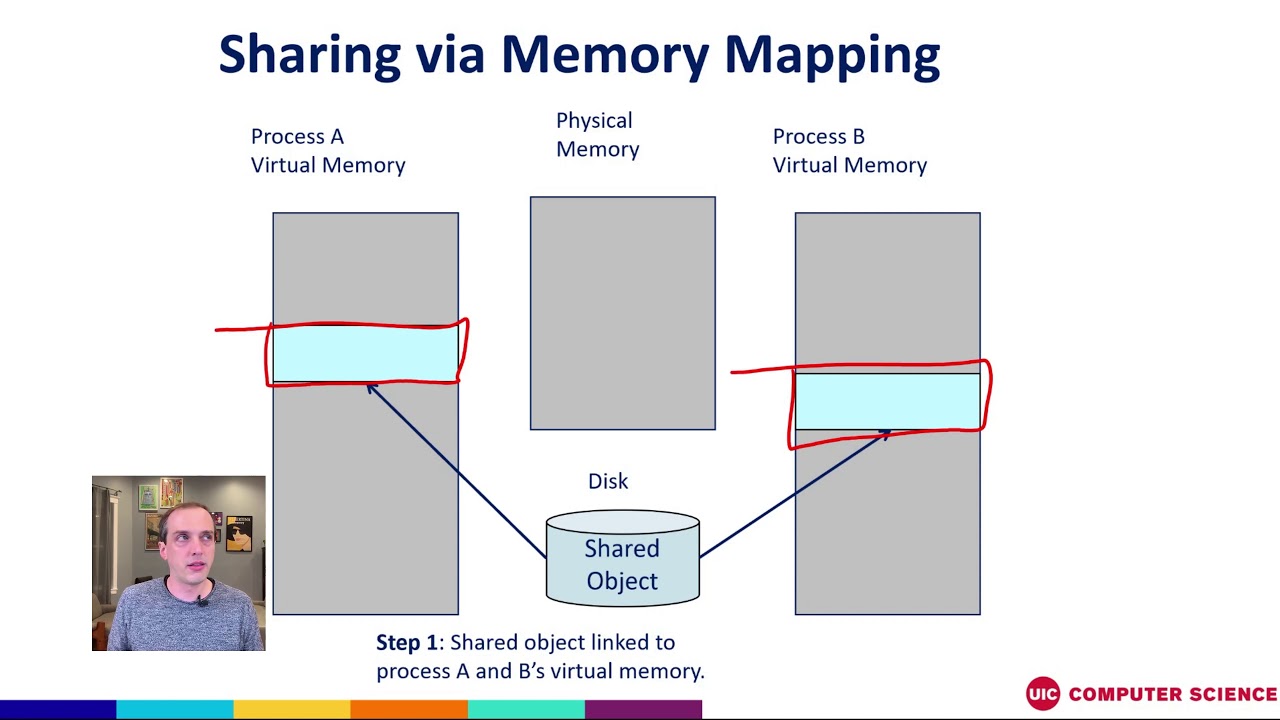
In the realm of high-performance computing, the ability to efficiently share data between processes is paramount. Traditional inter-process communication (IPC) mechanisms, while functional, often fall short in scenarios demanding rapid data exchange and low latency. Enter the mmap ring buffer, a powerful and versatile tool that leverages shared memory to facilitate seamless data transfer between processes.
Understanding the Fundamentals
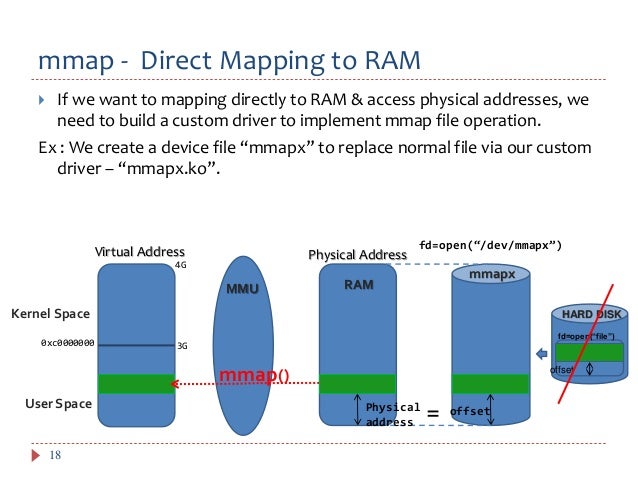
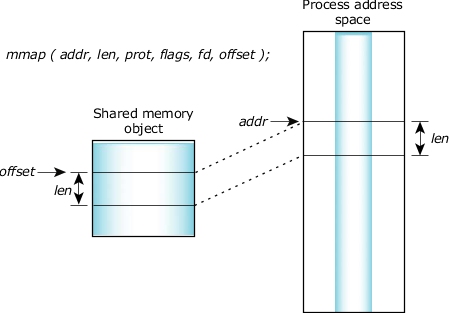
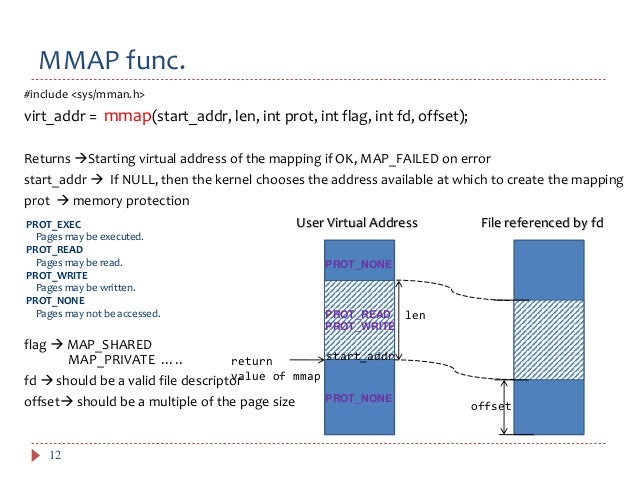
At its core, mmap (memory map) is a system call that allows a process to map a file or device into its virtual address space. This mapping enables direct access to the file’s contents as if they were part of the process’s own memory, eliminating the need for explicit read and write operations.
A ring buffer, on the other hand, is a circular data structure that facilitates efficient storage and retrieval of data. It operates on a first-in, first-out (FIFO) principle, where data is added to the tail of the buffer and removed from its head. The circular nature of the buffer allows for continuous data flow without the need for reallocation or memory fragmentation.
Combining these concepts, an mmap ring buffer emerges as a robust solution for inter-process communication. By mapping a shared memory region into the virtual address space of multiple processes, the ring buffer becomes accessible to all participating processes. Data written by one process can be seamlessly read by another, enabling efficient and synchronized data exchange.
The Advantages of mmap Ring Buffers
The use of mmap ring buffers offers several key advantages over traditional IPC mechanisms:
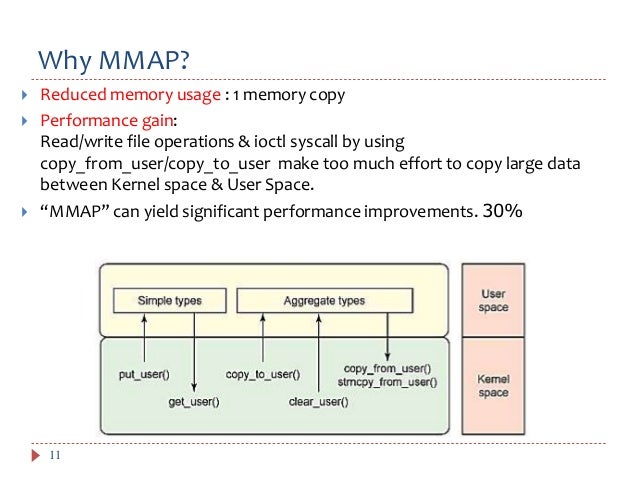
1. High Performance: By eliminating the overhead associated with system calls and context switching, mmap ring buffers achieve significantly higher performance compared to mechanisms like pipes or message queues. Data transfer occurs directly between processes’ memory spaces, resulting in minimal latency and increased throughput.
2. Efficient Memory Management: mmap ring buffers leverage the operating system’s memory management capabilities, minimizing the need for explicit memory allocation and deallocation. This simplifies memory management and reduces the risk of memory leaks or fragmentation.
3. Scalability: mmap ring buffers can easily scale to accommodate large datasets and numerous processes. The shared memory region can be dynamically resized to meet the demands of the application, allowing for flexible and efficient data handling.
4. Thread Safety: With proper synchronization mechanisms like mutexes or semaphores, mmap ring buffers can be made thread-safe, allowing multiple threads to access the shared memory region concurrently without data corruption.
5. Flexibility: mmap ring buffers can be used for a wide range of applications, from simple data sharing between processes to complex communication protocols. Their flexibility makes them a versatile tool for diverse programming needs.
Applications of mmap Ring Buffers
The versatility and efficiency of mmap ring buffers make them suitable for a broad range of applications:
1. High-Performance Data Pipelines: mmap ring buffers are ideal for constructing high-performance data pipelines, where data needs to be processed and transferred between multiple stages efficiently. Examples include image processing pipelines, video encoding/decoding systems, and real-time data analytics applications.
2. Inter-Process Communication: mmap ring buffers provide a reliable and efficient way for processes to communicate and share data. This is particularly valuable in scenarios where multiple processes need to collaborate on a task, such as distributed databases, parallel computing, and multi-threaded applications.
3. Producer-Consumer Pattern: mmap ring buffers are well-suited for implementing the producer-consumer pattern, where one or more processes produce data that is consumed by other processes. This pattern is common in asynchronous programming, message queues, and event-driven systems.
4. Shared Memory Databases: mmap ring buffers can be used to implement in-memory databases that provide fast access to data. This approach is particularly useful for applications requiring low latency and high throughput, such as caching systems, real-time data analysis, and gaming engines.
Implementing mmap Ring Buffers
Implementing an mmap ring buffer involves several key steps:
1. Shared Memory Allocation: The first step is to allocate a shared memory region using the shm_open() and ftruncate() system calls. This creates a file in the file system that represents the shared memory region.
2. Mapping the Shared Memory: The next step is to map the shared memory region into the virtual address space of each process using the mmap() system call. This provides each process with direct access to the shared memory.
3. Ring Buffer Implementation: Within the shared memory region, a ring buffer structure is defined, typically consisting of a data buffer, a head pointer, and a tail pointer. These pointers track the current read and write positions within the buffer.
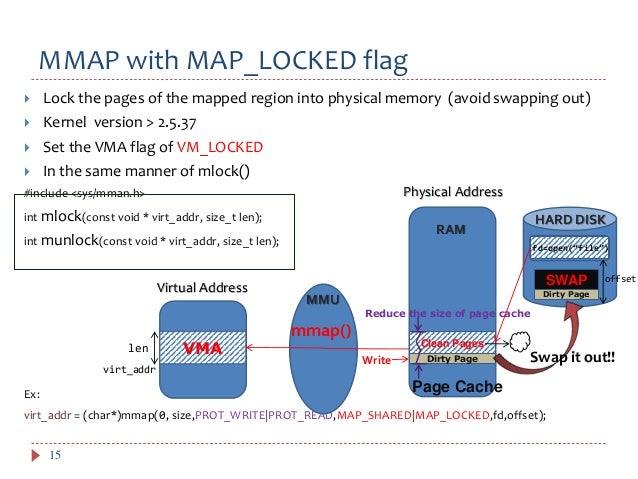
4. Synchronization Mechanisms: To ensure thread safety and prevent data corruption, synchronization mechanisms like mutexes or semaphores are used to control access to the shared memory region and the ring buffer.
5. Data Transfer: Processes can write data to the ring buffer by incrementing the tail pointer and writing data to the corresponding buffer location. Similarly, processes can read data from the ring buffer by incrementing the head pointer and reading data from the corresponding buffer location.
FAQs: Addressing Common Questions
1. What are the limitations of mmap ring buffers?
While powerful, mmap ring buffers have limitations:
- Memory Overhead: Large shared memory regions can consume significant memory resources, potentially impacting system performance.
- Synchronization Overhead: Synchronization mechanisms, while necessary for thread safety, introduce overhead that can affect performance.
-
Complexity: Implementing and managing
mmapring buffers can be complex, requiring careful attention to synchronization and memory management.
2. How do I choose the appropriate size for the shared memory region?
The size of the shared memory region should be large enough to accommodate the maximum amount of data that needs to be exchanged between processes. However, it should also be kept as small as possible to minimize memory overhead.
3. What are the best practices for using mmap ring buffers?
- Use synchronization mechanisms to ensure thread safety.
- Choose an appropriate size for the shared memory region.
- Monitor memory usage and performance to identify potential bottlenecks.
- Use a robust error handling mechanism to prevent data corruption.
4. Are there any alternatives to mmap ring buffers?
Alternative IPC mechanisms include:
- Pipes: Unidirectional data transfer between processes.
- Message Queues: Store and retrieve messages between processes.
- Sockets: Network-based communication between processes.
5. When should I use mmap ring buffers?
mmap ring buffers are best suited for scenarios where:
- High performance is required.
- Data needs to be shared efficiently between processes.
- A robust and scalable solution is needed.
Tips for Effective Implementation
- Optimize Memory Allocation: Allocate shared memory regions with the appropriate size to minimize overhead.
- Implement Robust Error Handling: Handle potential errors during shared memory allocation, mapping, and data transfer.
- Use Synchronization Mechanisms Carefully: Choose appropriate synchronization mechanisms and ensure their correct implementation to prevent data corruption.
- Monitor Performance: Monitor memory usage and performance metrics to identify potential bottlenecks and optimize the system.
-
Consider Alternatives: Evaluate alternative IPC mechanisms if
mmapring buffers are not suitable for the specific application.
Conclusion: The Power of Shared Memory
mmap ring buffers offer a powerful and efficient solution for inter-process communication, enabling high-performance data exchange and streamlined data flow. By leveraging shared memory and optimized data structures, they provide a robust and scalable approach to data sharing, making them valuable tools for diverse applications in the realm of high-performance computing. While implementing mmap ring buffers requires careful consideration of memory management, synchronization, and error handling, the benefits they offer in terms of performance, efficiency, and scalability make them a compelling choice for developers seeking to maximize the potential of their applications.
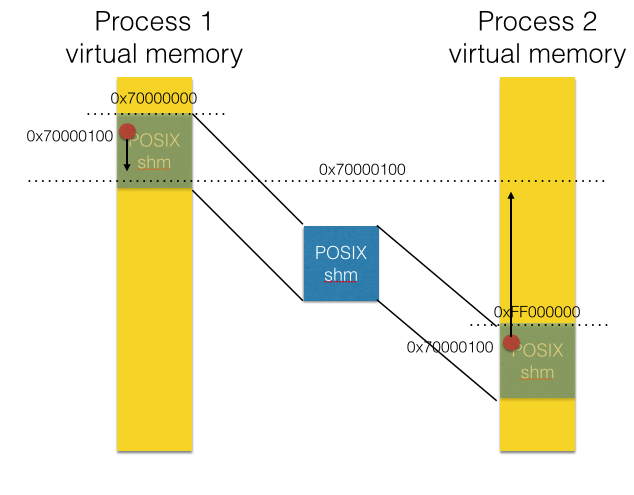
![[shared memory] performance comparison of mmap, shm and MappedByteBuffer](https://programmer.group/images/article/bfa2fbd495c2a4bd6ed095401195eb40.jpg)
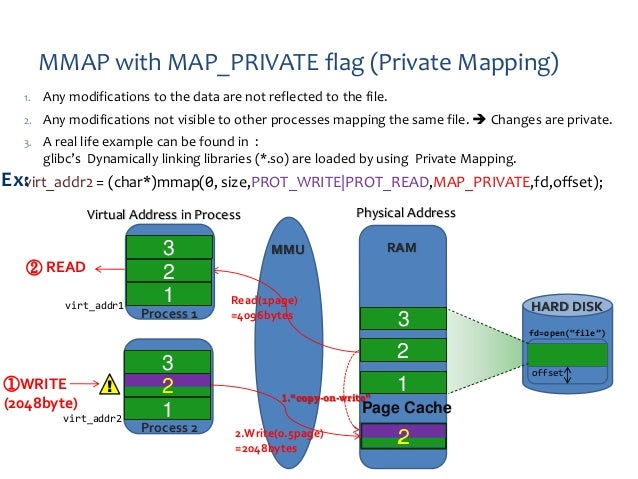
Closure
Thus, we hope this article has provided valuable insights into The Power of Shared Memory: Unlocking Efficiency with mmap Ring Buffers. We hope you find this article informative and beneficial. See you in our next article!