
The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter
Related Articles: The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter
- 2 Introduction
- 3 The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter
- 3.1 The Nature of Randomness in UMAP
- 3.2 Understanding the random_state Parameter
- 3.3 The Importance of Understanding Randomness in UMAP
- 3.4 FAQs about the random_state Parameter in UMAP
- 3.5 Tips for Using the random_state Parameter in UMAP
- 3.6 Conclusion
- 4 Closure
The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter
Uniform Manifold Approximation and Projection (UMAP) is a powerful dimensionality reduction technique widely used in data analysis and machine learning. It excels at preserving the local structure of high-dimensional datasets while projecting them into lower dimensions, facilitating visualization and downstream analysis. However, UMAP, like many other machine learning algorithms, relies on random processes during its execution. This inherent randomness is controlled through the random_state parameter, a crucial element that influences the final embedding and can significantly impact the analysis results.
The Nature of Randomness in UMAP
UMAP’s reliance on randomness stems from several key steps in its algorithm:
- Nearest Neighbor Search: UMAP begins by finding the nearest neighbors for each data point, a process that often involves randomized algorithms like k-d trees or ball trees. These algorithms, while efficient, introduce a degree of randomness in the neighbor selection.
- Stochastic Gradient Descent: UMAP employs stochastic gradient descent (SGD) to optimize the embedding. SGD updates the embedding based on a randomly selected subset of data points, introducing variability in the optimization process.
- Random Initialization: The initial embedding for the optimization process is often randomly generated, contributing to the overall randomness.
This inherent randomness in UMAP’s operation can lead to different embedding results with each run, even when presented with the same dataset. While this might seem like a drawback, it’s essential to understand the benefits and implications of this randomness.
Understanding the random_state Parameter
The random_state parameter in UMAP provides a mechanism to control this inherent randomness. It allows users to set a specific seed value for the random number generator used during the algorithm’s execution. This seed value ensures that the random processes within UMAP are deterministic, producing the same embedding result for multiple runs with the same random_state value.
Benefits of Specifying a random_state:
-
Reproducibility: Setting a
random_stateensures that the embedding process is reproducible. This is crucial for research and development, allowing researchers to validate their findings and compare results across different experiments. -
Debugging and Analysis: A fixed
random_statefacilitates debugging and analysis of the embedding process. It allows researchers to pinpoint the source of any variations in the embedding results by isolating the effects of different parameter settings or data transformations. -
Benchmarking: When evaluating different UMAP configurations or comparing UMAP with other dimensionality reduction techniques, using a fixed
random_stateensures that the results are comparable and not influenced by random variations.
When to Use a random_state:
-
Reproducible research and development: When the goal is to ensure consistent results across multiple runs, a fixed
random_stateis essential. -
Detailed analysis and debugging: When investigating the impact of different parameter settings or data transformations, a fixed
random_stateallows for isolating the effects of each variable. -
Benchmarking and comparisons: When evaluating different UMAP configurations or comparing UMAP to other dimensionality reduction techniques, a fixed
random_stateensures fair comparisons.
When to Avoid a random_state:
-
Exploratory data analysis: When the goal is to explore the data and gain insights without focusing on reproducibility, a random
random_statemight be preferable. -
High-dimensional datasets: For datasets with a very high number of dimensions, the impact of the
random_statemight be minimal, and the default random behavior might be sufficient.
The Importance of Understanding Randomness in UMAP
While the random_state parameter offers control over the randomness in UMAP, it’s crucial to remember that the algorithm’s inherent randomness is not necessarily a drawback. It can be seen as a source of diversity and robustness, allowing UMAP to explore different embedding solutions and potentially find better ones.
By understanding the nature of randomness in UMAP and the role of the random_state parameter, users can make informed decisions about how to utilize this powerful dimensionality reduction technique. Whether striving for reproducibility, debugging, or exploring different embedding solutions, the ability to control randomness through the random_state parameter empowers users to harness the full potential of UMAP for their specific data analysis needs.
FAQs about the random_state Parameter in UMAP
1. What happens if I don’t specify a random_state?
If you don’t specify a random_state, UMAP will use the default random number generator, which is initialized with a random seed. This means that every time you run UMAP, you’ll get a different embedding result.
2. Is it always necessary to specify a random_state?
No, it’s not always necessary. If you’re primarily interested in exploratory data analysis and are not concerned about reproducibility, you can leave the random_state unspecified. However, for research, development, or benchmarking, specifying a random_state is highly recommended.
3. Can I use the same random_state for different datasets?
Yes, you can use the same random_state for different datasets. However, it’s important to note that the embedding results will still be influenced by the specific characteristics of each dataset.
4. What if I get different embeddings with the same random_state?
If you get different embeddings with the same random_state, it’s likely due to numerical precision issues or subtle differences in the data. You can try increasing the n_neighbors parameter or adjusting other UMAP parameters to see if this resolves the issue.
5. How does random_state affect the performance of UMAP?
Specifying a random_state does not directly affect the performance of UMAP in terms of its accuracy or efficiency. However, it can influence the specific embedding that UMAP produces.
Tips for Using the random_state Parameter in UMAP
-
Start with a fixed
random_state: When first exploring a dataset or testing different UMAP configurations, it’s helpful to start with a fixedrandom_stateto ensure reproducibility. -
Experiment with different
random_statevalues: If you’re not satisfied with the initial embedding, try experimenting with differentrandom_statevalues to see if you can find a better embedding. -
Document your
random_statevalues: When publishing research or sharing your code, always document therandom_statevalues you used to ensure reproducibility. -
Consider the impact of data transformations: If you’re applying data transformations, such as scaling or normalization, remember that these transformations can influence the embedding results, even with a fixed
random_state.
Conclusion
The random_state parameter in UMAP is a powerful tool for controlling the inherent randomness in the algorithm. By understanding the nature of this randomness and how the random_state parameter works, users can make informed decisions about how to utilize this powerful dimensionality reduction technique for their specific data analysis needs. Whether striving for reproducibility, debugging, or exploring different embedding solutions, the ability to control randomness through the random_state parameter empowers users to harness the full potential of UMAP.


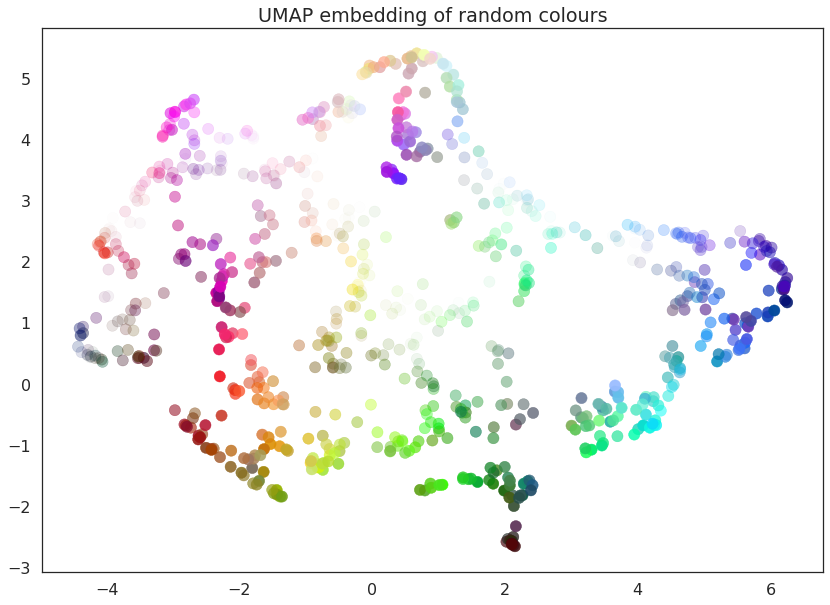
Closure
Thus, we hope this article has provided valuable insights into The Role of Randomness in UMAP: Understanding the Impact of the random_state Parameter. We hope you find this article informative and beneficial. See you in our next article!